Developing Notes of ASTJSON Library¶
After reading about the compiler, I feel intrigued as it challenges me with numerous design and implementation details. It's an exciting topic for me. Inspired by the APIs the Haskell Aeson library exposed, it's a good practice for me to write a toy library named xieyuschen/astjson to parse JSON string to AST in a slightly functional way. This is a developing notes page, and I record some reflections.
Basic Concepts¶
Lexer and Token¶
Tokens are the possible valid combinations of characters proclaimed by specification , like {, [, :, "string" and so forth.
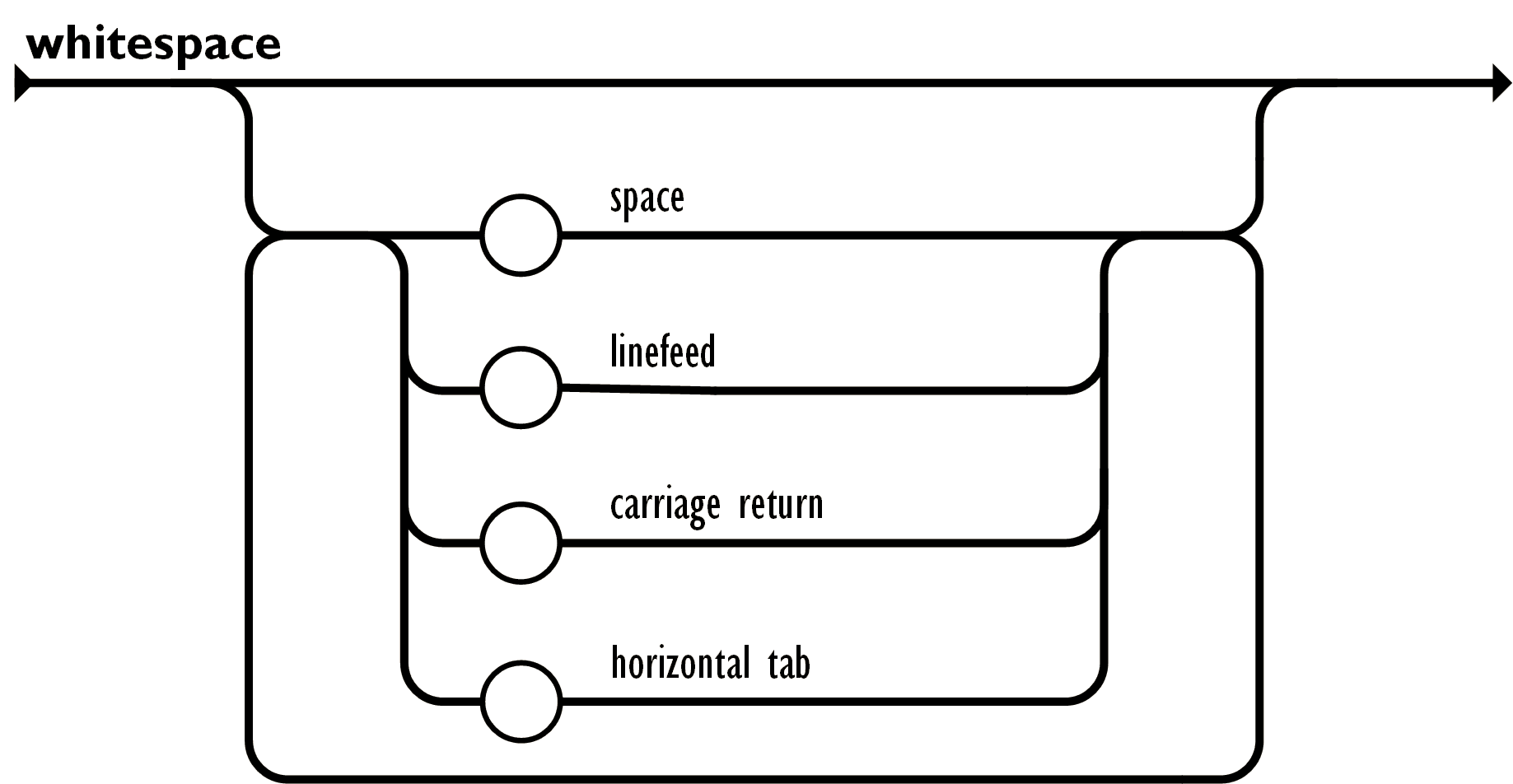
For example, the definition of Whitespace in json specification refers to all space, linefeed, carriage return and horizontal tab are Whitespace, which are nothing different in json.
A lexer is required to get tokens from raw bytes. It reads from the bytes and processes them as a state machine.
AST and Parser¶
AST is the structure that carries the value and type, which is nothing matter with tokens. When analyzed, AST represents the hierarchy relations of data but denotes nothing about what the original bytes look like. In other words, AST extracts the core information inside a series of bytes and discards trivial traits. Hence, we could convert an AST to any other configuration format, for example, yaml``,xml`, etc.
The parser is which processes tokens to AST. It reads the tokens in an orderly and checks the validation with the grammar mentioned in the specification.
Grammar¶
Grammar focuses on the rule about conversing from tokens to AST. It also overlooks the detailed characters because that's charged in the lexer. Grammar stressed the validation of compositions of multiple tokens. For example, after a { token, the grammar expects a String token with any Whitespace tokens among them. It‘s indifferent about which character stands for Whitespace token but concerned about whether the composition of tokens({ and String with any whitespace among them) satisfies the grammar.
Lexer Implementation¶
Terminals(Tokens)¶
We need to define terminals(tokens) before writing the lexer. The tokens in JSON are pretty simple, as it doesn't allow variables and complex syntax.
// token represents the json token.
// currently, token only supports to the limited json value and limits primitive
// types only.
type token struct {
tp Type
// the token value is [ leftPos, rightPos)
// index starts at 0
leftPos, rightPos int
// hasDash and isFloat only make sense for tkNumber because we don't
// want to lose precise
hasDash, isFloat bool
}
Type Definition
An optimization here is made for number as we suffer a precise lose while parsing the max number of uint64. Before optimization, I used float64 to store all numbers, and it works well in several cases. However, when the max uint(\(2_{64} - 1\)) is assigned to a float64 and cast to `uint64`` back, it overflows.
Hence, I defined the token with more details to benefit the Number type. I check whether the dot or negative mark exists while parsing the number. Moreover, I treated the Number as the default case if no matched case was found while scanning the bytes.
Lexer¶
A lexer receives a series of bytes and generates lots of tokens. Hence, there are two sentries for a lexer to proceed bytes. The predictive scanning is used during parsing bool and null types, as the only valid tokens for t, f, and n characters are true, false, and null.
The lexer has some details while scanning the string and number.
While scanning for the string type, we must solve some cases below.
- backforward slash
\. - hex digital like
\ucdef
Adding additional checks could solve them. Moreover, predictive scanning is helpful here, and the cases are very limited.
When scanning for the number type, the float and negative is stored for the AST parser.
AST Definition¶
JSON has limited types of nodes, which are Array, Object, Null, Bool, String, and Number. Hence, their definitions are simple. But there are still some considerations while defining.
Facade of AST Node¶
Because Go language doesn't support sumtype, such as type Number = uint64 | int64 | float64, an agent to represent all types is required. Inside astjson lib, I defined Value as the agent:
// NodeType represents an AST node type
//
//go:generate stringer -type=NodeType
type NodeType uint
const (
Number NodeType = iota
Null
String
Bool
Object
Array
)
// Value is the concrete AST representation
type Value struct {
NodeType
// AstValue stores the real value of an AST Value
// the literal type(Number, String, Bool and Null) stores them by value
// the Object and Array stores them by pointer
AstValue interface{}
}
We could cast the AstValue inside Value to the corresponding type with the meta information. What's more, the library provides some utility functions to cast the AstValue to a concrete type. The functions panic when fail to cast, with the same behaviors of the methods of reflect.Value like Int(), Bool() and so forth.
Why Reflect Cast Panic if Not Satisfy
The reflect.Value holds the type and values inside it as well. It provides some utility methods to cast the agent to a concrete type. However, what if the method is called with a wrong desired type? The reflect package chooses to panic to clean the return value, instead of returning an error.
Number AST Node Definition¶
As mentioned above, to solve the precise loss, the token carries more details if it's a number token.
Number AST Definition
It provides utilities to retrieve the correct value with a certain type as you like.
func (n NumberAst) GetInt64() int64
func (n NumberAst) GetUint64() uint64
func (n NumberAst) GetFloat64() float64
The Other AST Node Definitions¶
The Object in JSON is a map with String key and any possible types as its value. Initially, I define a map[*Value]*Value to store the key-value pair. However, as the key is String forever, I directly use string as the key type.
type NullAst struct{}
type BoolAst bool
type StringAst string
type ObjectAst struct {
KvMap map[string]Value
}
type ArrayAst struct {
Values []Value
}
The concern for literary types Null, Bool and String is defining type alias or a new type. I chose to define a new type:
- option1(chosen): define a new type:
type BoolAst bool - option2: define an alias type:
type BoolAst = bool
I decided to make all types consistent and defined by the library, so the option1 was picked up.
todo topics
- Parser Implementation
- Decoder Implementation
- Walker Implementation